Service Definitions
Services are typically defined as tasks that run continuously. For example, the following might be considered a service:
require 'sinatra'
get '/hi' do
"Hello World!"
end
# run via:
# $ gem install sinatra
# $ ruby hi.rb
Above we have a webservice. It takes some input, responds with some output and runs until terminated.
The following could also be considered a service:
#!/usr/bin/env ruby
def fibonacci(n)
return n if n <= 1
fibonacci(n - 1) + fibonacci(n - 2)
end
puts fibonacci(ARGV[0])
# run via:
# $ ./fibonacci.rb 10
# => 55
Above we have a background service. It takes some input, responds with some output, and runs to completion.
The only differences between the above services are:
- One is a web process that binds to a port
- One can continue to respond to requests, while the other services a single request before terminating
Termination, Completion, and Exit Codes
Services can, and sometimes should, be terminated. In certain cases, you might have a service that is behaving poorly, consuming more memory/cpu that you’d otherwise want to allocate to it. In those cases, termination may be the appropriate route.
A good example of an expected termination is a PHP background worker. Consider the following:
#!/usr/bin/env php
$some_array = array();
while (true) {
$value = rand(0, 10);
$data[] = $value;
printf("New value is {$value}\n");
usleep(10);
}
# run via:
# ./worker.php
The above code will:
- aggregate a random value into an array, present the output to the user
- repeat loop
Because we are building up a datastructure, at some point this script will exhaust all memory available to PHP - perhaps less, depending upon your php.ini. This blatant memory leak could be fixed, but serves as a trivial example of what could happen in your otherwise immaculate production code.
Uncontrolled use of system resources is undesired because it increases the chance that something will break catastrophically. Resources should be monitored and alerted upon, such that issues like the above can be fixed before they become threats to the stability of your system.
A trivial fix would be to monitor memory usage inline:
#!/usr/bin/env php
$some_array = array();
while (true) {
$memory = memory_get_usage();
if ($memory > 1000000) {
printf("exiting run due to memory limit\n");
exit;
}
$value = rand(0, 10);
$data[] = $value;
printf("New value is {$value}\n");
usleep(10);
}
# run via:
# ./worker.php
Now the process terminates itself. Ideally we do the resource check outside of the script, to centralize such code, but for our infrastructure, the above might be sufficient.
Termination
A process can be terminated by a user or by itself. Our example above terminates itself. Our hi.rb sinatra service is terminated by a user. Neither has a “completed” state. That is to say, neither defines the number of data points it could generate, and thus will run until terminated.
Because the above statement is woefully inadequate, you’ll likely want to have some helpful reading material with which to tell me I am useless as a computer scientist:
If we ran a process in the background - using nohup for instance - you would potentially get the following output:
$ nohup ./worker.php &
=> [1] 1337
The output on the second line above contains a process ID, which can be used to inspect the process. A trivial use of this id would be to kill it:
# HUP: hang up
kill -1 1337
# KILL: non-catchable, non-ignorable kill
kill -9 1337
Your code could attempt to trap certain signals, responding to them as necessary. For example, perhaps your script wants to de-allocate all used memory on HUP, or reload configuration.
While I hate sites like cyberciti.biz, I’d be lying if I said I didn’t personally find them useful.
Completion
If a command runs to completion, that means we previously defined a final state we want the application to be at. For example, perhaps we have a script that generates some csv files, uploads them to ftp, and then plays “happy birthday” on the company radio.
Keep this in mind. Not all services will run forever. Some will have a predefined final state. That doesn’t mean they are not a service.
Exit Codes
If you read nothing else, read this. All services are running processes, when they exit, they should use a proper exit code.
In bash:
- Exit code of
0denotes success. - Non-zero exit denotes failure.
127means a command was unable to be found128means a command was found, but could not be executed.- Shell built-ins return
2to note that you are a fucktard and didn’t use the command properly.
This isn’t hard people. Please respect the above, as it makes it much simpler to chain commands. Most programming languages that allow execution of arbitrary commands in a pseudo-shell will respect exit codes, so your program should as well.
If you have a script that validates json, and I run it, if I see error output but the exit status is
0, scripting becomes much harder. Parsing logs is a difficult problem, and one should not have to resort to string processing in order to figure out if a command worked.
Requirements for a service
Services have, at the base case, a set of language, configuration, and environment requirements, etc. Consider the following:
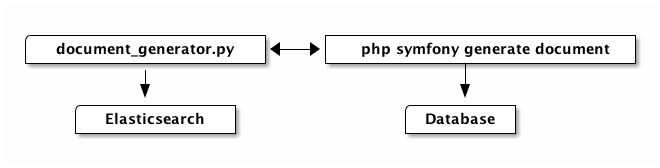
Our document generator service requires:
Pythonfordocument_generator.pyPHPfor thephp symfony generate:documentcommand- A database of some sort,
MySQLin our case Elasticsearch
So we’ll need:
- Languages: [
Python,PHP] - Environment variables: [
MYSQL_URL,ELASTICSEARCH_URL,ENV,PHP_GENERATE_DOCUMENT_LOCATION] - Codebases: [
api,symfony-app]
We have memory requirements of some sort for this system, and since we are running this on a system with other services, we should have some idea as to how many “requests” this system can respond to.
One thing to note is the above isn’t necessarily all you need to run a process within your process manager. You may want to define any of the following:
commandenvironment_variablesassigned portworking_directoryrespawn_countwhen_to_runnumber_of_processessystem_packagesuserorgroupto run as
And all of the above should be described cleanly by you and your developers for services run in production. Having a well-defined interface for accessing services will make debugging services much easier for both operations and the development team. Placing this information in everyone’s face in a trivial manner will make it easier to reason about how a service is run, what it’s SLA will be like, and interdependencies between services.
Services as command groups
I like the following description of what a service is:
Services are not a single process or bound port, they are a definition of what is required for each of those things.
In our document_generator service, we are running multiple processes. They all form a single service, even though they may also be standalone services.
Services are composable. That is to say, you can mix and match services as necessary, to create better services down the road.
Because services are composable, you should define all the requirements for a service in a single location. This may result in duplication of information - perhaps multiple services run the same command - but will also ensure that when you say “I want to run service X”, the entire service is running.
If only a portion of a service is running, then the service is not running and should be considered down.
Services depending upon other services
This goes back to my previous post. I think I was wrong in stating “Service x needs Y, what service provides Y” where Y is an environment variable. Instead, I wish to restate this:
Service X depends upon Service Y, give me everything Service Y provides
Typically, a command will provide only a single resource locator, but a service may provide multiple commands, each with their own resource locator(s). This is an important distinction from what I stated previously.
Unique Resource Locators
Resource locators should be unique across your infrastructure. If you have multiple services providing API_URL, I believe this is incorrect. You might instead have SANTAMARIA_URL and AUTOCOMPLETE_URL. You wouldn’t name two components of your infrastructure api, so you shouldn’t commit the same sin with exported configuration.